
Garena黄智凯:利用Docker构建自动化运维
- 2016-08-22 09:14:00
- 先知 转贴
- 25093
黄智凯:Docker构建自动化运维
讲师简介
来自新加坡最大的互联网公司Garena,曾就职于新浪和奇虎360,DBA背景成长的他同时一直致力于运维平台自动化的建设和创新。
大家可能对Garena比较陌生,Garena最开始做游戏运营,现在在东南亚市场上也有了很多自己的产品,包括一些社交软件和最近很火的直播,同时也有在做电商平台。
分享主题:利用Docker构建自动化运维

首先介绍一下我们的平台生态圈,最核心的是中间部分,最初平台是用来跑Web服务的,所以我们以Jenkins作为核心部署组件管理Docker容器。Docker容器是在swarm节点也就是swarm集群。Swarm,Compose,Machine三个组件可以用来做云集群管理。这三大组件我们唯一没有使用的是machine,因为machine的主要优势是在公有云上调动API创建云主机。我们有自己的IDC,所以没用Machine,出于安全考虑,我们用Docker Registry,它可以实现版本控制,也可以控制机器上的打包。
右边是整个生态圈中的监控系统,主要跟大家介绍一下Consul,Consul是一个分布式高可用系统。和同类产品比如zookeeper相比,它的优势就是提供完善的Http和DNS接口,由于Consul服务的重要性,我们不允许出现任何故障,于是部署了三台节点,他们互相时间实现仲裁,保证在某一个节点宕机的情况下,依然会正确选举出Leader,整个集群依然是可用的。从开始平台只跑Web网站,后来扩展到缓存等,所有服务都是高可用的。
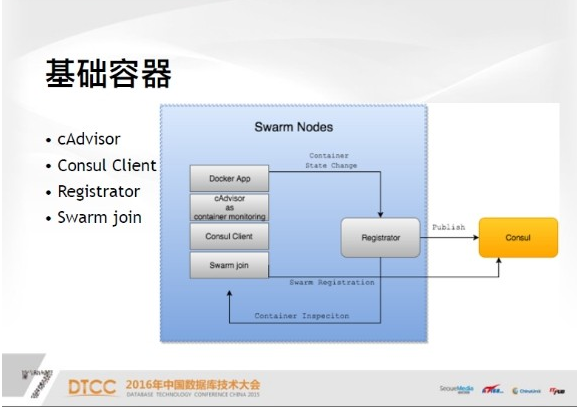
接下来介绍集群的基础节点——Swarm节点,你可以认为是宿主机,每一台宿主机都有基础的云服务器支撑。服务技术单元是每个Docker APP,可以是主站也可以是任何服务。只要定义好,就可以直接注册到Consul里。接下来介绍一些基础容器,一是cAdvisor,这是谷歌提供的一款监控软件,应该算比较成熟的监控软件。
二是Consul Client,实际上这不是必要的,如果以后集群规模扩大,Consul服务端有可能会成为瓶颈,因为如果大量的Swarm节点都向Consul查询,会给主服务器带来很多压力,本地区的Consul服务延时更小,也能减少服务器的压力。
再说Swarm join,它的作用是把节点注册到整个集群,你可以认为整个集群是一个抽象的资源池。最重要的基础容器是Registrator,这之中有很多关于服务器的工具,都是高可用服务生命周期,如果发生变化,会把容器信息注册到consul中。简单的说就是拿到容器的元数据,元数据包括三点,一是分离,二是容器在宿主机上的IP,三是容器在主机上的监听,把这三个注册到consul中,后续就可以从存储中拿到Docker的所有元数据。
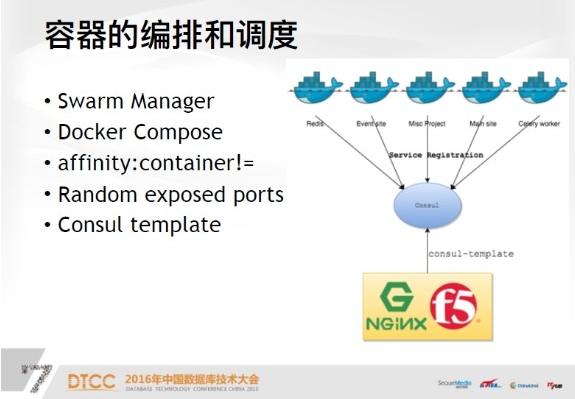
接下来说容器的编排和调度,先说Swarm Manager,可以认为是一个指挥官也就是管理机。
下面是Docker Compose,后面有一个配置文件的sample,所以说每一个Docker服务启动之后,就会有一个随机的服务端口,这个信息会注册到consul里面,此时会有一个工具Consul template,是官方提供的一个工具。
他可以查询你的服务名,依据我们目前的标准,一个服务名对应是一个网站的域名,到后端查询这个域名,就知道Docker服务是跑在哪些节点上了,将源数据从consul中取出来之后,template一个新的配置文件并放到Nginx proxy上实现负载均衡。

下面说一下配置管理Ansible,做项目之前,我们已经有了将近一年的使用经验。所以做这个时写了一些任务,上手也很快。比如说建立镜像,不同的项目上线,要给它不同的镜像,像Python网站需要不同的依赖,我就会给它很多不同的镜像。
它是有版本控制的,版本控制的好处就是如果现在打了一个新的镜像,上线有问题的话,可以直接回滚到上一个版本,这是镜像回滚,下面还会介绍代码是如何回滚的。
第二步,初始化服务器,你只需要输入IP,基础服务就可以装好,基础环境就已经配置完成。第三步是代码同步,第四步是添加监控及Dashboard。

下面就说一下测试环境和线上环境,因为这个最初是做web的,所以每个都是以域名为单元。
当时就想着如果做测试和线上分离的环境怎么办,定义的标准就是域名前加一个test域名。这个IP在访问控制上只限制在内部网站上可以访问,所以实现分离就是使用不同的consul集群,我们有线上consul集群和测试consul集群。
如果你要调用Ansible去配置管理它们的话,只需要给不同的consul集群不同的参数,比如要刷新配置的话,你给一个测试环境的consul集群,它取到的元数据肯定跟你线上取到的不一样,所以同一个Ansible任务可以管理两套环境。
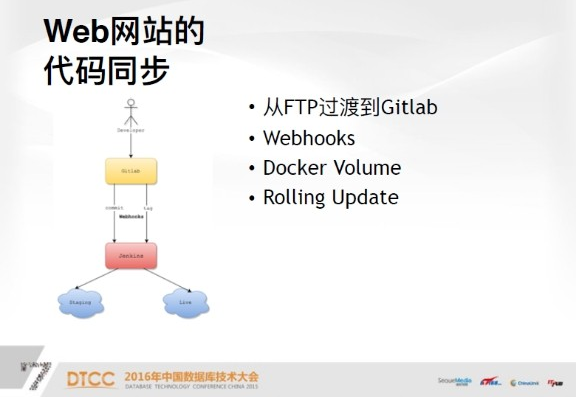
下面说一下web网站的代码同步,最开始我们是使用FTP,项目user根据域名定义。这样就导致如果一个人管理很多域名的话,就会收到很多不同的FTP用户名和密码。所以最后我们把这套网站移到了Gitlab上,Gitlab提供了一个很友好的功能,它提供的Webhooks可以很好的解决运维和开发之间的隔离,相当于发布网站代码时,运维完全不需要干预任何事,一旦网站上线,它就可以开心地去写代码,上线是通过两个Webhooks,commit和tag,这是Gitlab自带的两个hook,这两个hook在提交代码时,会自动触发jenkins任务,它会在测试环境上部署代码。如果你在Gitlab上直接打tag,它会在live环境部署代码,所以运维完全不需要干预整个过程。
下面是Docker Volume,它的概念就是,首先我把web虚拟机上的目录映射到容器中,这样的好处是代码上线的话,半分钟之内在线上或测试就可以实现代码同步,而且开发写代码时,每天可以commit很多次,每一次都能及时看到测试环境代码所反映的效果。如果将代码打入镜像,它的劣势是打的时间成本太长,回滚起来也可能相对慢一些。如果使用volume的话,可以把日志打到宿主机上,这样可以直接收到日志的实时反馈,因为Docker天生是没有SSH的,很多开发者开始会跟我们抱怨,就想查一个问题,但是看不到任何日志,不好debug。所以我们解决开发者的痛点,让开发者在网站上能够实时看到日志。
第四是Rolling Update,这在静态网站中是不存在的,很多网站需要重启服务才能看到改动。这样的话,首先因为后端有多个容器,先把第一个容器stop掉,然后再刷新配置,永远保证后端是有容器提供服务的。这样的话来回三次,做到代码的平滑升级,这就是Rolling Update。
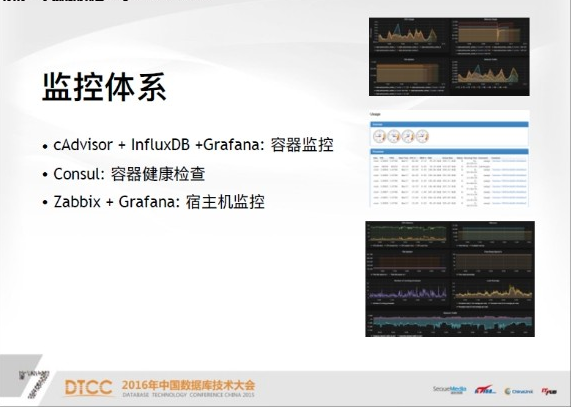
下面说一下监控,监控是容器的监控,是cAdvisor、influxDB和Grafana,如果大家对容器熟的话,会知道这是一个比较成熟的方案。这个图就是我们以容器维度来看每一个容器的健康状况,CPU内存等情况,这个图中的服务,可以看到有五个容器来支撑,一般来说,五个容器是负载均衡的,所以看到的曲线相对来说差不多一致。
下面是cAdvisor监控,从宿主机的维度来看,有很多Docker服务,因为这个页面很长,我只截取了最上面的部分,其实可以从每一个点看子容器的各个状态。第三就是宿主机监控,这个监控是取得Zabbix数据源。所以你可以看到CPU内存,网络负载等你所关心的情况,可以看到当前数据反映出宿主机大概是一个什么样的情况。
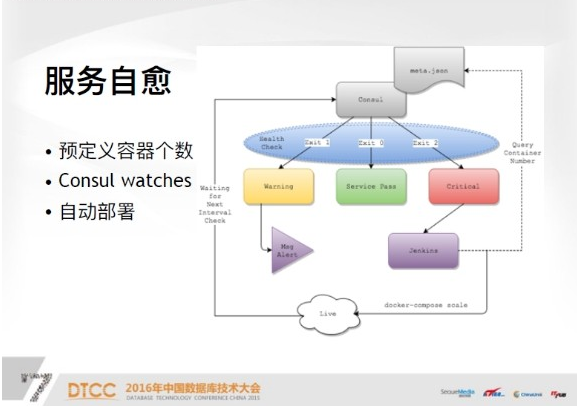
服务自愈是比较关键的部分,服务自愈主要有三个概念,第一需要定义容器部署,比如你的系统现在需要三个容器支撑,或者是四个,或者是两个,一般来说至少两个,这是用Json文件定义在监控机上的,你定义一个服务名,这个服务需要多少容器支撑,这个时限是使用Consul Watches也就是健康检查,健康检查有三个状态,脚本可以自己写,自己定义,如果你的访问码是0,就是Service正常状态,如果访问码是1,就是warning状态,如果访问码是2,就是critical状态。
首先访问码是1,比如说我现在自定义一种情况,假设线上跑的容器个数超过了预定义容器个数,你认为是资源浪费,所以你现在可以定义warning状态,你会收到短信报警,你可能需要人工干预,到底是什么问题导致我现在跑的容器比我想要的还多,这种情况一般出现的比较少。主要出现的情况就是critical状态,也就是典型的一台宿主机挂掉了,之后上面所有的容器,比如说跑了几十个容器全部挂掉了,所以在进行下一次Consul健康检查时,会发现你的服务没有达到预期的定义,这时候就会收到watches,执行服务自愈操作。
服务自愈操作首先会检查当前的Consul集群,服务或是线上服务是否符合规定的Json文件格式。如果不符合,就使用Docker Compose Scale,也就是Swarm Manager管理节点,重新调动一个新的容器,这基本上也是秒级创建。所以我们在下一个检查也就是60秒之后,重新等待Consul的下一次健康检查。一般来说,如果检查通过,第一次如果是critical状态,下一次基本会实现自愈。利用这个功能,你也可以对宿主机进行平滑升级。
比如我们之前做Docker版本升级,从1.8多升到1.9,当时只需要在整个集群中把宿主机去掉,也就是把基础容器替换掉或者kill掉,以一种正常的方式把它干掉之后,只需要把Docker给关掉。这样在Consul进行下一次检查时,就会发现很多容器坏掉,然后就会触发Jenkins重新部署操作。这样对机器或者软件包的升级就变得非常简单。相当于很优雅的离开集群,升级完之后,再把宿主机加入到集群就OK了。

下面说一下0.6版本的新特性,我们也是利用这个特性给Regis平台做高可用方案。之前我也一直在想怎么做Redis Master/Slave切换,Tag的作用就是动态给某个容器贴标签,你可以认为这个是角色,这个角色可以是master,也可以是slave,我们改了Registrator,也就是注册consul服务,让它支持这个参数。

下面就是对F5的一些操作,右下角是F5的基本配置,这边是一些语法,首先查询service name,它会查询consul服务里到底有几个容器提供服务。
如果这些容器有tag master,就会把这个服务设成10,如果是slave,就会设成9,就是说F5永远会把流量打到Priority-group大的的节点上,也就是F5永远会把流量打到master上,直到master挂掉或者不响应,F5会自动把流量切到slave上。
所以如果集群挂掉了,master挂掉了,不用担心,只需要重启一个新的容器直接slave off到老的slave上,然后把老的重新打成master,把新的打成slave就OK了。

最后说一下我们遇到的问题,一是Consul Reload,它一直在Github上,有很多人都说这个问题发生的原因是,每次需要更新consul配置,但是触发Consul Reload的同时,会调用watches相当于服务部署脚本。这个带来的问题是需要很小心的写watches脚本,而不是说Zabbix收到部署任务就去部署,得实际查一下线上环境是不是真的少于标准环境。
二是Zabbix active log,我们是监控Consul,当log达到预值的时候,即使在10分钟之内,它的状态没有发生变化,我们也把log级别调一下,这应该是Zabbix现在也一直存在的。
三是Docker compose,最开始用的时候没有用Registry,所以每一个目录底下都会有一个Dockerfile,docker实际上和compose是可以动态建立的,这带来了一个问题,如果你想把容器扩展到两个或三个的话,它就会直接fail。这是一个先天缺陷,后来我们用docker hub或者内部registry,就比较完美的避免了这个问题。
四是F5,它只使用一个IP地址,一旦服务多了之后,会出现一些连接莫名断掉的情况,最后查的话,是因为F5上的snat端口已经耗尽。他们让我创建一个snat池,然后把一些可用的IP加进去,目前有8个IP,算下来有将近50万连接可以支撑。
我今天的分享到此结束,谢谢大家!
| 联系人: | 王春生 |
|---|---|
| Email: | chunsheng@cnezsoft.com |
