
Kubernetes管理员的11条安全军规
- 2018-08-22 10:00:00
- Andrew Martin
- 转贴:
- docker.io
- 10914
【译者的话】Kubernetes博客上的一篇关于Kubernetes安全防护的最佳实践。
自从Kubernetes项目开天辟地以来, 其安全性已经取得了长足的发展, 但它目前依然还有些要点值得注意。 本文列举了11条军规来帮助让你的集群在稳定运行时加固安全,以及在受到危害时对抗冲击。这些军规涵盖了对控制面板的配置, 对工作负载的防护, 乃至对未来的展望。
第一部分:控制面板
作为Kubernetes的核心大脑, 控制面板全面展示了在集群中所有容器和Pod的运行情况。 它可以直接调度新的Pod(可能包含对宿主节点有root权限的容器), 还可以用来读取集群中所有的secret。 控制面板中展示的内容非常重要, 需要好好的保护起来以免发生意外泄漏和恶意访问——无论这些内容是被访问时, 在存储状态, 又或者是在网络中传输时。
1. 全面启用TLS
应该在所有组件上都使用TLS, 以防止网络嗅探, 验证服务器端的身份,以及在启动双向TLS认证时验证客户端的身份。
需要注意的是, 一些组件在安装时可能会有默认设置启用http端口。管理员需要熟悉每个组件的设置从而识别出这种潜在会产生不安全流量的情况。
这份来自Lucas Käldström的网络图展示了几处应该配置TLS的地方, 包括组件与主节点的交互, 以及Kubelet与API Server的交互。 Kelsey Hightower的大作Kubernetes The Hard Way中对此提供了详细的手工操作指导。 etcd的安全模型文档里也有细致描述。
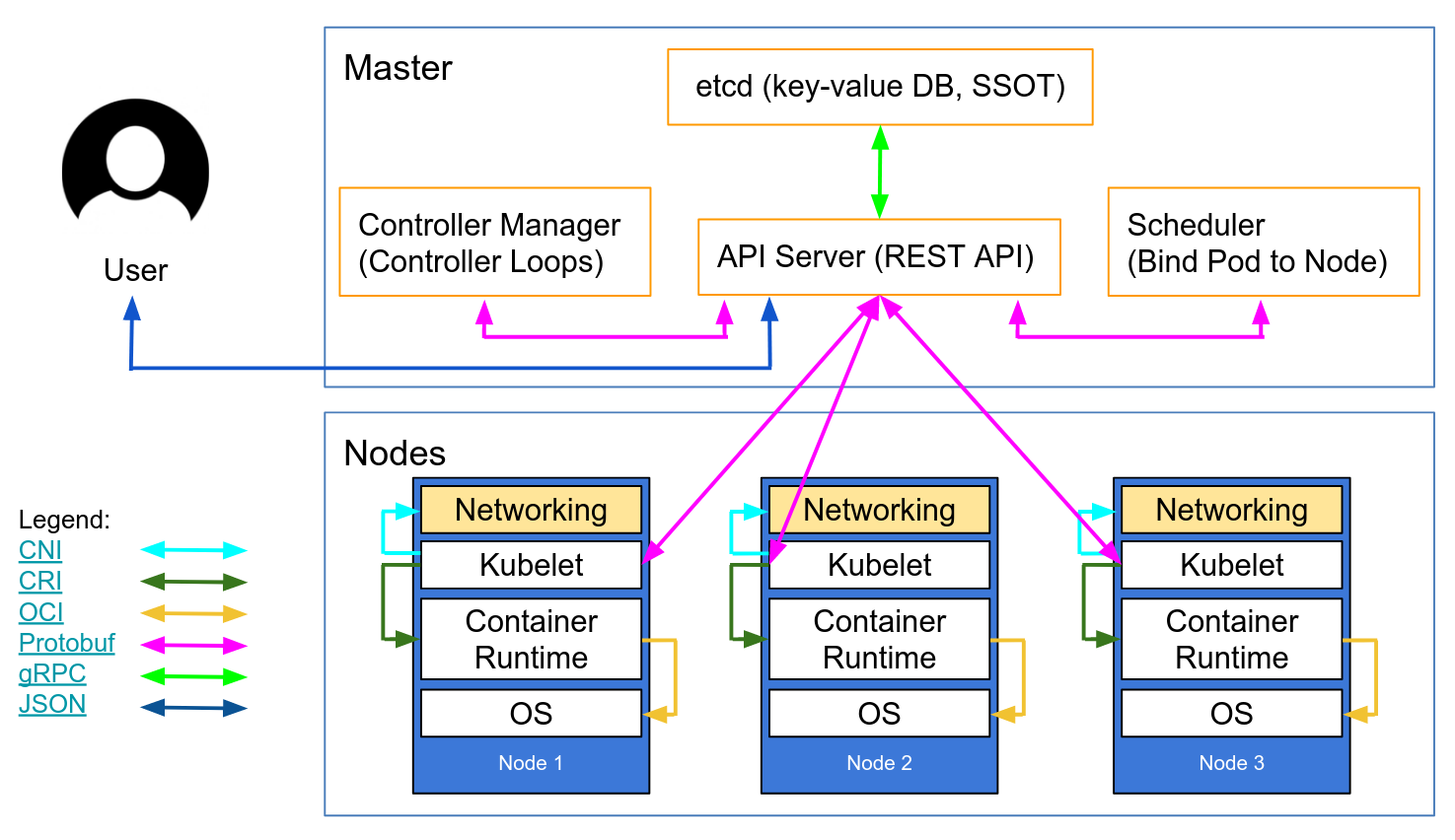
自动伸缩Kubernetes的节点在过去是非常困难的操作, 因为每个节点都需要一个TLS的密钥来连接主节点, 而将密钥打包放进基础镜像又不是一个好的实践方式。 现在Kubelet的TLS引导程序提供了让新的kubelet在启动时生成证书签名申请的能力。
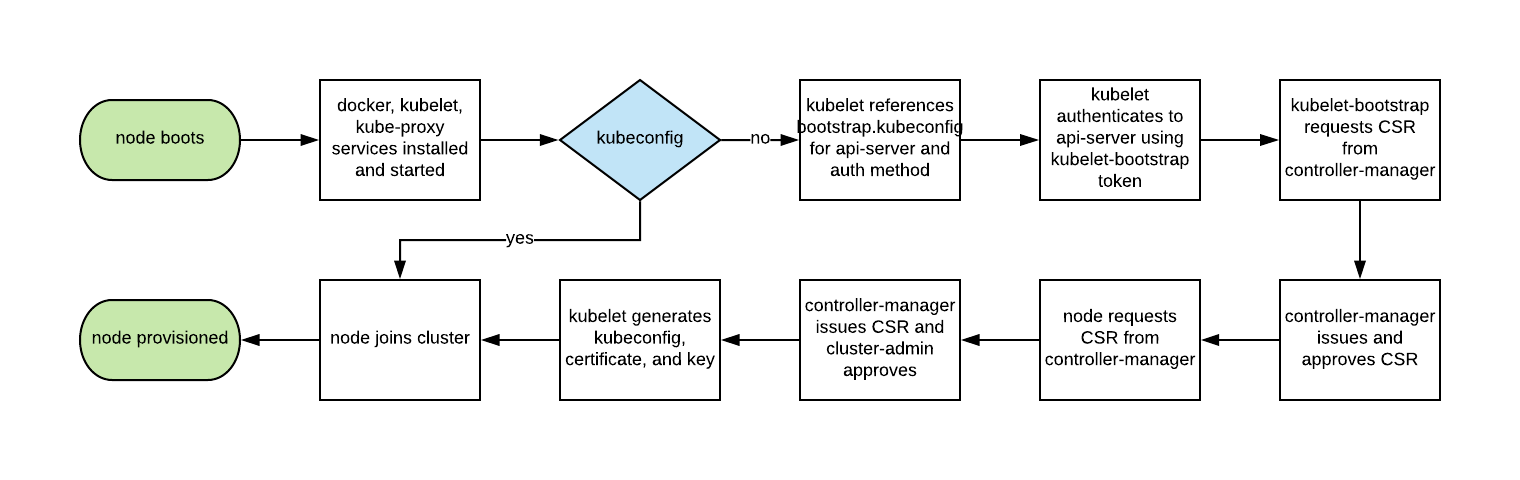
2. 以最小特权原则设置RBAC, 关闭ABAC, 以及监控日志
RBAC提供了细粒度的规则管理功能, 以限制用户对资源(比如namespace)的访问。
ABAC于Kubernetes的1.6版开始为RBAC所取代,已不建议启用。 在普通的Kubernetes集群中通过设置以下启动参数在API Server中启用RBAC:
--authorization-mode=RBAC
而在GKE中通过另一个参数来禁用ABAC:
--no-enable-legacy-authorization
网上有很多不错的例子和文档描述了如何在集群中使用RBAC策略。 除此之外, 管理员还可以通过audit2rbac生成的审计日志来分析调优RBAC规则。
如果将RBAC规则设置得过大或者不正确, 一旦集群中出现有问题的Pod会对整个集群产生安全威胁。 RBAC规则应该基于最小特权原则进行维护, 并持续地加之以审阅和改善。 这应被团队视为技术负债的清除手段被整合进开发流程之中。
审计日志功能(1.10中为beta阶段)提供了可定制化地对集群各组件的访问流量内容(例如请求和响应)及元数据(例如发起用户和时间戳)记录日志的功能。 日志等级可以根据组织内的安全策略进行调整。 在GKE上也有相应的设置来配置这个功能。
对于读取类请求(比如get, list和watch) ,只有请求内容会被记录在审计日志中, 响应内容不会保存。 对于涉及到敏感数据(比如Configmap和Secret)的请求, 只有元数据会被记录。 对于其他类型的请求, 请求和相应对象都会被记录。
切记:如果将审计日志保留在集群内部, 在集群已被入侵时会有安全威胁。 像这样的所有安全相关的日志都应转移到集群之外, 以避免出现安全漏洞时被篡改。
3. 为API Server启用第三方认证
在一个组织内部通过集中化的手段管理认证和授权(又被称为单点登录)有助于管理用户的添加, 删除以及一致的权限控制。
通过将Kubernetes与第三方的身份验证服务(比如Google和GitHub)整合,这样可以使用第三方平台的身份保证机制(包括双因子验证等机制), 以避免管理员不得不重新配置API Server来添加或删除用户。
Dex是个OpenID Connect(OIDC)和OAuth2.0的身份服务组件。 它带有可插拔的连接器。 Pusher公司通过这个机制将Dex作为认证链的中间件将Kubernetes与其他第三方认证服务关联。 除此之外还有其他工具可以达成类似目的。
4. 将etcd集群隔离出来并加上防火墙控制
etcd中存储了集群的状态和secret, 对Kubernetes而言是至关重要的组件。 它的防护措施应该与集群的其他部分区别处理。
对API Server的etcd拥有写权限相当于获取了整个集群的root权限。 甚至仅通过对etcd的读取操作都可以相当简单地自行提权。
Kubernetes的调度器会搜索etcd找出那些已定义但还没被调度到节点上的Pod, 然后把这样的Pod发送到空闲的Kubelet节点进行部署。 在Pod信息被写进etcd之前, API Server会检查提交的Pod定义。 因此一些有恶意使用者会直接把Pod定义写入etcd, 以跳过许多诸如PodSecurityPolicy这样的安全机制。
无论是etcd集群的节点与节点, 还是节点与API Server, 他们的通信都应该配置TLS证书, 并且etcd集群应部署在专属的节点之上。 etcd集群与Kubernetes集群间也应该设置防火墙, 以避免由于私钥被盗而被从工作节点上发起攻击。
5. 定期替换密钥
定期替换密钥和证书是一条安全方面的最佳实践。 这样能减小当密钥被盗时所遭受的损害范围。
Kubernetes会在某些现有证书过期时创建新的证书签名申请来自动替换Kubelet的客户端和服务器端证书。
但是API Server用来加密etcd数据的对称密钥是无法自动替换的。 它只能手工替换。 这样的操作需要有对主节点操作的权限, 因此托管Kubernetes服务(比如谷歌的GKE和微软的AKS)会自行解决这个问题而无需管理员操心。
第二部分:工作负载
通过对控制面板实施最小化可用安全策略,可以使集群工作得更安全。 但这样还不够。 打个比方, 对于一艘装运了危险货物的船,船上的集装箱也必须加以防护,这样在出现意外事故或破坏时集装箱还能承载货物。对于Kubernetes的工作负载对象(Pod, Deployment,Job和Set等)也是一样。 它们在部署时还是可信的,然而当面对外网流量时总还是会有被攻破的风险。 要减轻此类风险,除了针对工作负载对象实施最小特权原则外,还需要加固它们运行时的配置。
6. 使用Linux的安全功能以及Kubernetes的Pod安全规则
Linux内核提供了许多互相有功能重叠的安全扩展(capabilities, SELinux, AppArmor, seccomp-bpf)。 他们可被配置用来为应用提供最小特权。
像bane这样的工具可以用来生成AppArmor的配置文件和seccomp的docker-slim配置文件。 然而用户需要详细测试自己应用的所有路径, 验证这些配置对应用是否会造成副作用。
而Pod安全规则可以用来授权使用Kubernetes的安全扩展和其他安全指令。 这些规则描述了一个Pod提交到API Server后所必须遵守的最小安全契约。 这些契约包括了安全配置,提权标志,以及共享主机网络,进程或进程间通信的命名空间。
这些安全规则相当重要, 因为他们有助于防止容器内的进程超越其隔离边界。 Tim Allclair提供的PodSecurityPolicy范例相当详尽。 你可以自定义这个范例, 将其用在自己的使用场景里。
7. 静态分析YAML文件
在使用Pod安全规则来控制Pod访问API Server的同时, 也可以在开发工作流中使用静态文件分析来构筑组织的合规需求或满足风险偏好。
在Pod类型(比如Deployment, Pod, Set等)的YAML文件中不应该存放敏感数据, 而包含敏感数据的Configmap和Secret应该由诸如vault(通过CoreOS提供的operator), git-crypt, sealed secret或者云厂商提供的密钥管理服务来进行加密处理。
静态分析YAML配置可以对运行时的安全情况构建一条基准线。 以下是kubesec工具为某个资源生成风险评分的例子:
{
"score": -30,
"scoring": {
"critical": [{
"selector": "containers[] .securityContext .privileged == true",
"reason": "Privileged containers can allow almost completely unrestricted host access"
}],
"advise": [{
"selector": "containers[] .securityContext .runAsNonRoot == true",
"reason": "Force the running image to run as a non-root user to ensure least privilege"
}, {
"selector": "containers[] .securityContext .capabilities .drop",
"reason": "Reducing kernel capabilities available to a container limits its attack surface",
"href": "https://kubernetes.io/docs/tasks/configure-pod-container/security-context/"
}]
}
}
而kubetest工具是个针对Kubernetes的YAML文件的单元测试框架。 代码例子如下:
#// vim: set ft=python: def test_for_team_label(): if spec["kind"] == "Deployment": labels = spec["spec"]["template"]["metadata"]["labels"] assert_contains(labels, "team", "should indicate which team owns the deployment") test_for_team_label()
以上这些工具都通过将检查和验证工作在软件开发周期中提前(shift left)到更早的开发阶段的方式, 使开发人员能更早地获得对于代码和配置的反馈, 以避免提交在之后的人工或自动检查中被退回。这样也可以减少引入更多安全实践的障碍。
8. 使用非root的用户运行容器
运行在root用户下的容器大多拥有了大大超过其所承载的服务需要的权限。 当集群被侵入时,这样的容器会让攻击者有能力执行更进一步的破坏。
容器技术依然基于传统的Unix安全模型, 叫做自主访问控制(简称DAC)。在这个模型之下,所有东西都是文件, 而权限是可以被赋予用户或用户组。
用户命名空间在Kubernetes下并没有启用, 这意味着容器中的用户表会被映射到宿主机的用户表中, 而在容器里由root身份运行的进程相当于在宿主机上也是以root身份运行。 尽管说我们有层级安全机制来防范容器发生问题, 但在容器中用root身份运行进程依然是不推荐的做法。
许多容器镜像使用root用户运行一号进程。 如果这个进程被攻破, 那么攻击者在容器中就有了root的权限, 从而会轻易放大由于集群误配置造成的安全漏洞。
Bitnami公司在将容器镜像迁移到非root用户这方面做了很多工作(主要由于OpenShift平台默认要求非root身份运行容器)。参考他们提供的文档可以降低管理员实施类似迁移的难度。
下列Pod安全规则的代码片段给出了防止容器中的进程以root身份运行, 以及防止进程提权到root身份的方法:
# Required to prevent escalations to root. allowPrivilegeEscalation: false runAsUser: # Require the container to run without root privileges. rule: 'MustRunAsNonRoot'
非root的容器无法绑定小于1024的端口(可以通过配置内核参数CAP_NET_BIND_SERVICE来启用), 但使用service的特性可以使对外端口配置为1024以下。 在以下例子中,MyApp这个应用在容器中绑定了8443端口,而service将相关流量代理到443这个端口中对外暴露应用:
kind: Service apiVersion: v1 metadata: name: my-service spec: selector: app: MyApp ports: - protocol: TCP port: 443 targetPort: 8443
在用户命名空间在Kubernetes中可用之前,或者非root功能在容器运行时组件中获得直接支持之前, 使用非root用户运行容器依然是推荐的做法。
9. 使用网络规则
默认状态下, Kubernetes中Pod与Pod之间的网络是互通的。 可以通过使用网络规则来对此加以限制。
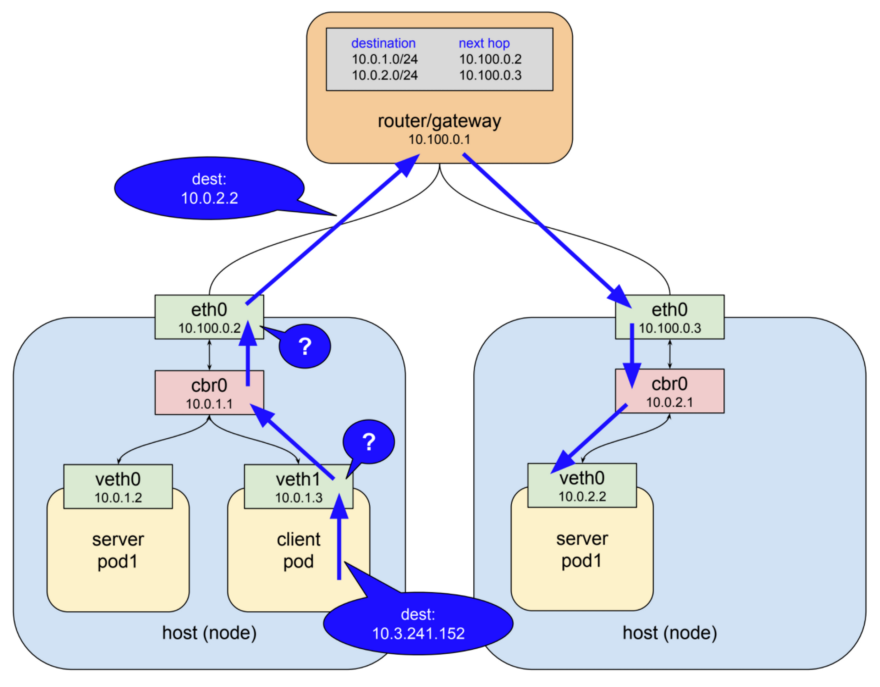
kubernetes-networking.png
传统的服务一般给每个应用配置静态IP和端口范围。 这样的静态IP一般很少会改变,从而会被当作服务的一种标识来对待。 因此传统服务可以通过防火墙来加以限制和保护。 容器为了能快速失败快速重新调度,一般很少使用固定IP,而是通过使用服务发现的机制来替代。 容器这样的特性使得防火墙会更难配置和审查。
由于Kubernetes将所有系统状态都存储在etcd里, 只要CNI网络插件支持网络规则, 借助etcd中的数据就可以配置动态防火墙。 当前Calico, Cilium, kube-router, Romana和Weave Net这些插件都能支持网络规则。
值得注意的是,这些网络规则是失效关闭的(fail-closed), 因此在下列YAML中缺少podSelector配置意味着这个规则会应用到所有容器:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: default-deny spec: podSelector:
下列的网络规则的例子描述了如何关闭除了UDP 53(DNS端口)之外的所有对外流量。 这样也防止了进入应用的连接——这是因为网络规则是有状态面向连接的, 同一个网络连接中应用对外请求的响应也依旧会返回到应用中。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: myapp-deny-external-egress
spec:
podSelector:
matchLabels:
app: myapp
policyTypes:
- Egress
egress:
- ports:
- port: 53
protocol: UDP
- to:
- namespaceSelector: {}
Kubernetes的网络规则并不能被应用到DNS名字上。 这是因为一个DNS名字会可能被轮询调度解析到许多个IP地址,或者依据调用IP动态被解析到不同的目标IP地址, 而网络规则只能被应用到静态的IP或podSelector(也就是Kubernetes的动态IP机制)上。
安全上有一条最佳实践建议一开始对Kubernetes的namespace先拒绝所有流量, 然后再逐渐添加路由允许应用能通过测试场景。 这样做是非常复杂的, 可以通过下列ControlPlane公司出品的netassert这个开源工具来帮助达成最佳实践。 netassert是一个安全运维工作流方面的网络安全工具, 通过高度并发运用nmap来扫描和嗅探网络:
k8s: # used for Kubernetes pods deployment: # only deployments currently supported test-frontend: # pod name, defaults to `default` namespace test-microservice: 80 # `test-microservice` is the DNS name of the target service test-database: -80 # `test-frontend` should not be able to access test-database’s port 80 169.254.169.254: -80, -443 # AWS metadata API metadata.google.internal: -80, -443 # GCP metadata API new-namespace:test-microservice: # `new-namespace` is the namespace name test-database.new-namespace: 80 # longer DNS names can be used for other namespaces test-frontend.default: 80 169.254.169.254: -80, -443 # AWS metadata API metadata.google.internal: -80, -443 # GCP metadata API
云厂商的元数据API一般也会是被攻击的源头之一(参见最近发生的Shopify受攻击的案例), 因此也需要有专门的测试来确定这一类API在容器网络中被关闭,以避免误配置的可能。
10. 扫描容器镜像和运行IDS(入侵检测系统)
Web服务器作为它所部署的网络上的一个可被攻击的切入口,它镜像上的文件系统需要被完全扫描,以避免存在已知的漏洞被攻击者利用来取得远程控制容器的权限。使用IDS可以检测已知漏洞。
Kubernetes通过一系列的Admission Controller来控制Pod类型的资源(如Deployment等)是否能被部署进集群。 Admission controller会检验每个被提交进来的Pod的定义,或者有时会修改Pod定义的内容。 现在已经支持后台webhook挂载外部应用。
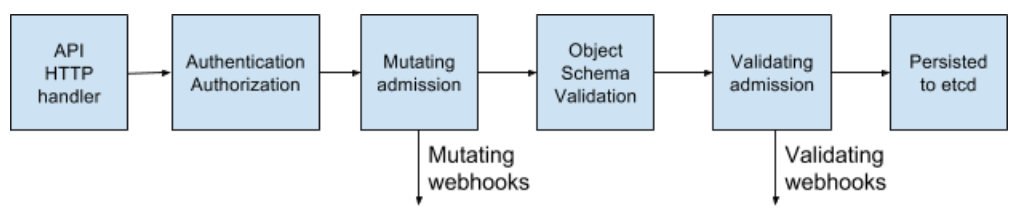
Webhook功能可以和容器镜像扫描工具结合起来。 在容器被部署进集群之前扫描镜像内容。 一旦未通过扫描检查, 容器便会被Admission Controller拒绝部署。
使用工具扫描容器镜像中是否包含已有的漏洞, 这样能减小攻击者利用公开漏洞(CVE, Common Vulnerabilities & Exposures)的时间窗口。 像CoreOS出品的Clair和Aqua出品的Micro Scanner都应该被整合到部署管道中, 以避免部署的容器中包含致命漏洞。
像Grafeas这样的工具可以存储镜像的元数据, 用来针对容器的特有签名(基于内容寻址的散列哈希)进行持续的合规与漏洞检查。 通过这个签名来扫描本地容器镜像等同于扫描部署在生产环境的容器, 这样就可以持续地做本地检查而不需要连接到生产环境中。
而未知的瞬时攻击漏洞(Zero Day)永远会存在。 为了应对这样的威胁, 需要在集群中部署一些诸如Twistlock, Aqua和Sysdig Security这样的工具。而另外一些IDS会检测出容器中发生的不寻常的行为, 暂停或者终止这样的容器。 典型的工具有Sysdig出品的开源规则引擎Falco。
第三部分: 展望未来
目前看来服务网格当属安全在“云原生进化(cloud native evolution)”发展中的下一阶段形态。 当然真正应用服务网格尚需时日。 迁移工作涉及到将应用层中含有的相关复杂逻辑转移为依赖服务网格的基础构件, 而企业也会很想详细理解迁移和运用服务网格相关的最佳实践。

11. 使用服务网格
服务网格是通过类似Envoy和Linkerd这样的高性能边车(sidecar)代理服务器在集群中组建应用间加密网络的基础设施。 它提供了流量管理, 监控和规则控制的能力而无需微服务为此修改代码。
服务网格意味着微服务中的安全与网络管理相关的代码可以被去除, 而这部分责任将被转移到经过实战验证的公共组件中。 之前通过Linkerd就已经可以达成这样的功能。 如今由Google, IBM和Lyft联合推出了Istio在服务网格领域也可以作为一个可选方案。 Istio通过基于SPIFFE规范的Pod间相互进行身份识别的能力以及其他一系列的功能, 来简化服务网格这个下一代网络安全的部署。 在“永不信任,始终验证”(Zero Trust)的网络模型中, 每次交互都应在互信TLS(mTLS, mutual TLS)下发生, 以保证交互双方不仅链路安全,而且身份已知。 这样的话或许就没有必要使用传统的防火墙或者Kubernetes的网络规则了。
对于仍怀有传统网络思维的那些人来说,我们预计向云原生安全原则的思维转变不会容易。 此处推荐阅读来自SPIFFE项目委员会的Evan Gilman撰写的Zero Trust Networking这本书来了解这一领域的入门知识。
Istio 0.8 LTS版本已经推出。 这个项目正快速接近1.0版本的发布(译者:Istio 1.0版已于2018年7月31号发布)。 其版本编号习惯会与Kubernetes遵循的模型相同:核心版本稳定增长, 每个API都会通过自己版本中的alpha/beta来描述其稳定性。 可以期待Istio在之后几个月的采用率会有上升。
结语
云原生应用拥有一系列带有细粒度配置能力的轻量级安全组件来控制工作负载与基础架构。 这些工具的威力和灵活性对管理员来说既是祝福又是诅咒。 如果自动化安全能力不足, 这些工具很容易会暴露不安全的网络流量,导致容器或隔离结构爆发问题。
防护工具层出不穷, 但管理员仍需警惕误配置的潜在可能, 并尽量减少对外易受攻击的点。
然而如果安全性要求会减缓组织交付功能的速度, 那么安全就永远无法成为一类需求。通过在软件交付流程中应用持续交付的原则, 可以让组织在不影响业务的情况下也能合规和治理目标,实现持续审计。
在有完整的测试套件的支持之下,想要在安全方面快速迭代是非常容易的。 而这样的迭代并非是用定点运行渗透测试来运作,而是持续安全(Continuous Security)。 持续安全通过持续的管道验证的方式来保证组织的受攻击点清晰, 相关风险明确并能有效地被管理起来。
以下推荐一下ControlPlane公司的服务:如果您需要在组织内启动持续安全的流程, 或者需要Kubernetes安全和运维的培训,又或者想要把服务和开发流程迁移到安全的云原生方式, 请联系我们。
作者介绍: Andrew Martin是@controlplaneio公司的联合创始人。 他一般会在@sublimino上发表一些关于云原生安全的推文。
原文链接:11 Ways (Not) to Get Hacked(翻译:Cosine)
| 联系人: | 王春生 |
|---|---|
| Email: | chunsheng@cnezsoft.com |
